
Tradução automática
O que é tradução automática?
Os sistemas de tradução automática são aplicativos ou serviços on-line que usam tecnologias de aprendizado de máquina para traduzir grandes quantidades de texto de e para qualquer um dos idiomas suportados. O serviço traduz um texto "de origem" de um idioma para um idioma "de destino" diferente.
Embora os conceitos por trás da tecnologia de tradução automática e as interfaces para usá-la sejam relativamente simples, a ciência e as tecnologias por trás dela são extremamente complexas e reúnem várias tecnologias de ponta, em particular, aprendizagem profunda (inteligência artificial), big data, linguística, computação em nuvem e APIs da Web.
Desde o início da década de 2010, uma nova tecnologia de inteligência artificial, as redes neurais profundas (também conhecidas como aprendizagem profunda), permitiu que a tecnologia de reconhecimento de fala atingisse um nível de qualidade que permitiu que a equipe do Microsoft Translator combinasse o reconhecimento de fala com sua principal tecnologia de tradução de texto para lançar uma nova tecnologia de tradução de fala.
Historicamente, a principal técnica de aprendizado de máquina usada no setor era a tradução automática estatística (SMT). A SMT usa análise estatística avançada para estimar as melhores traduções possíveis para uma palavra, considerando o contexto de algumas palavras. A SMT tem sido usada desde meados dos anos 2000 por todos os principais provedores de serviços de tradução, inclusive a Microsoft.
O advento da tradução automática neural (NMT) causou uma mudança radical na tecnologia de tradução, resultando em traduções de qualidade muito superior. Essa tecnologia de tradução começou a ser implementada para usuários e desenvolvedores na final de 2016.
As tecnologias de tradução SMT e NMT têm dois elementos em comum:
- Ambos exigem grandes quantidades de conteúdo traduzido pré-humano (até milhões de frases traduzidas) para treinar os sistemas.
- Nenhum deles funciona como dicionário bilíngue, traduzindo palavras com base em uma lista de possíveis traduções, mas traduzem com base no contexto da palavra que é usada em uma frase.
O que é o Translator?
Serviços de tradução e fala, parte do Serviços cognitivos coleção de APIs, são serviços de tradução automática da Microsoft.
Tradução de texto
O Translator tem sido usado por grupos da Microsoft desde 2007 e está disponível como uma API para clientes desde 2011. O Translator é usado extensivamente na Microsoft. Ele está incorporado nas equipes de localização de produtos, suporte e comunicação on-line. Esse mesmo serviço também pode ser acessado, sem custo adicional, a partir de produtos conhecidos da Microsoft, como Bing, Cortana, Microsoft Edge, Escritório, SharePoint, Skypee Yammer.
O Translator pode ser usado em aplicativos da Web ou do cliente em qualquer plataforma de hardware e com qualquer sistema operacional para realizar a tradução de idiomas e outras operações relacionadas a idiomas, como detecção de idioma, texto para fala ou dicionário.
Aproveitando a tecnologia REST padrão do setor, o desenvolvedor envia o texto de origem (ou áudio para tradução de fala) para o serviço com um parâmetro que indica o idioma de destino, e o serviço envia de volta o texto traduzido para ser usado pelo cliente ou aplicativo da Web.
O serviço Translator é um serviço do Azure hospedado nos data centers da Microsoft e se beneficia da segurança, escalabilidade, confiabilidade e disponibilidade ininterrupta que outros serviços de nuvem da Microsoft também recebem.
Tradução de fala
A tecnologia de tradução de fala do Translator foi lançada no final de 2014, começando com o Skype Translator, e está disponível como uma API aberta para os clientes desde o início de 2016. Ela está integrada ao recurso ao vivo do Microsoft Translator, ao Skype, à transmissão de reuniões do Skype e aos aplicativos do Microsoft Translator para Android e iOS.
A tradução de fala agora está disponível por meio do Microsoft Speech, um conjunto completo de serviços totalmente personalizáveis para reconhecimento de fala, tradução de fala e síntese de fala (conversão de texto em fala).
Como funciona a tradução de textos?
Há duas tecnologias principais usadas para a tradução de textos: a antiga, Statistical Machine Translation (SMT), e a mais recente, Neural Machine Translation (NMT).
Tradução automática estatística
A implementação da tradução automática estatística (SMT) do Translator foi desenvolvida com base em mais de uma década de pesquisa de linguagem natural na Microsoft. Em vez de escrever regras criadas manualmente para traduzir entre idiomas, os sistemas de tradução modernos abordam a tradução como um problema de aprendizado da transformação de texto entre idiomas a partir de traduções humanas existentes e aproveitando os avanços recentes em estatística aplicada e aprendizado de máquina.
Os chamados "corpora paralelos" funcionam como uma Pedra de Roseta moderna em proporções enormes, fornecendo traduções de palavras, frases e expressões idiomáticas no contexto de muitos pares de idiomas e domínios. Técnicas de modelagem estatística e algoritmos eficientes ajudam o computador a resolver o problema de decifração (detectar as correspondências entre o idioma de origem e o idioma de destino nos dados de treinamento) e decodificação (encontrar a melhor tradução de uma nova sentença de entrada). O Translator une o poder dos métodos estatísticos às informações linguísticas para produzir modelos que generalizam melhor e resultam em traduções mais compreensíveis.
Devido a essa abordagem, que não depende de dicionários ou regras gramaticais, ele fornece as melhores traduções de frases em que pode usar o contexto de uma determinada palavra em vez de tentar realizar traduções de uma única palavra. Para traduções de palavras isoladas, o dicionário bilíngue foi desenvolvido e pode ser acessado por meio de www.bing.com/translator.
Tradução automática neural
Melhorias contínuas na tradução são importantes. No entanto, os aprimoramentos de desempenho atingiram um patamar com a tecnologia SMT desde meados da década de 2010. Ao aproveitar a escala e a potência do supercomputador de IA da Microsoft, especificamente o Microsoft Cognitive Toolkit, o Translator agora oferece rede neural (LSTM) que possibilita uma nova década de aprimoramento da qualidade da tradução.
Esses modelos de rede neural estão disponíveis para todos os idiomas de fala por meio do serviço Speech no Azure e por meio da API de texto, usando a ID da categoria 'generalnn'.
As traduções por redes neurais diferem fundamentalmente na forma como são realizadas em comparação com as traduções SMT tradicionais.
A animação a seguir mostra as várias etapas pelas quais as traduções por redes neurais passam para traduzir uma frase. Devido a essa abordagem, a tradução levará em conta o contexto da frase completa, em vez de apenas uma janela deslizante de algumas palavras que a tecnologia SMT usa, e produzirá traduções mais fluidas e com aparência de tradução humana.
Com base no treinamento da rede neural, cada palavra é codificada em um vetor de 500 dimensões (a) que representa suas características exclusivas em um determinado par de idiomas (por exemplo, inglês e chinês). Com base nos pares de idiomas usados para treinamento, a rede neural definirá por si mesma quais devem ser essas dimensões. Elas poderiam codificar conceitos simples como gênero (feminino, masculino, neutro), nível de polidez (gíria, casual, escrito, formal etc.), tipo de palavra (verbo, substantivo etc.), mas também quaisquer outras características não óbvias derivadas dos dados de treinamento.
As etapas pelas quais as traduções de redes neurais passam são as seguintes:
- Cada palavra, ou mais especificamente o vetor de 500 dimensões que a representa, passa por uma primeira camada de "neurônios" que a codificará em um vetor de 1000 dimensões (b) que representa a palavra no contexto das outras palavras da frase.
- Depois que todas as palavras tiverem sido codificadas uma vez nesses vetores de 1000 dimensões, o processo é repetido várias vezes, cada camada permitindo um melhor ajuste fino dessa representação de 1000 dimensões da palavra no contexto da frase completa (ao contrário da tecnologia SMT, que só pode levar em consideração uma janela de 3 a 5 palavras)
- A matriz de saída final é então usada pela camada de atenção (ou seja, um algoritmo de software) que usará essa matriz de saída final e a saída de palavras traduzidas anteriormente para definir qual palavra, da frase de origem, deve ser traduzida em seguida. Ele também usará esses cálculos para eliminar palavras desnecessárias no idioma de destino.
- A camada de decodificador (tradução) traduz a palavra selecionada (ou, mais especificamente, o vetor de 1000 dimensões que representa essa palavra no contexto da frase completa) em seu equivalente mais apropriado no idioma de destino. A saída dessa última camada (c) é então enviada de volta à camada de atenção para calcular qual palavra seguinte da frase de origem deve ser traduzida.

No exemplo mostrado na animação, o modelo de 1000 dimensões com reconhecimento de contexto de "o" codificará que o substantivo (casa) é uma palavra feminina em francês (A casa). Isso permitirá a tradução apropriada para "o" para ser "la" e não "le" (singular, masculino) ou "les" (plural) quando chega à camada do decodificador (tradução).
O algoritmo de atenção também calculará, com base na(s) palavra(s) traduzida(s) anteriormente (nesse caso, "o"), que a próxima palavra a ser traduzida deve ser o sujeito ("casa") e não um adjetivo ("azul"). Isso é possível porque o sistema aprendeu que o inglês e o francês invertem a ordem dessas palavras nas frases. Ele também teria calculado que, se o adjetivo fosse "grande" em vez de uma cor, para não invertê-las ("a casa grande" => "la grande maison").
Graças a essa abordagem, o resultado final é, na maioria dos casos, mais fluente e mais próximo de uma tradução humana do que uma tradução baseada em SMT jamais poderia ser.
Como funciona a tradução de fala?
O Translator também é capaz de traduzir a fala. Essa tecnologia está exposta no recurso Translator live (http://translate.it), os aplicativos do Tradutor, o Skype Translator e também é inicialmente disponibilizado apenas por meio do recurso Skype Translator e nos aplicativos do Microsoft Translator para iOS e Android, essa funcionalidade agora está disponível para os desenvolvedores com a versão mais recente da API aberta baseada em REST disponível no portal do Azure.
Embora possa parecer um processo simples, à primeira vista, criar uma tecnologia de tradução de fala a partir dos tijolos tecnológicos existentes, isso exigiu muito mais trabalho do que simplesmente conectar um mecanismo de reconhecimento de fala homem-máquina "tradicional" existente ao mecanismo de tradução de texto existente.
Para traduzir adequadamente a fala "fonte" de um idioma para um idioma "alvo" diferente, o sistema passa por um processo de quatro etapas.
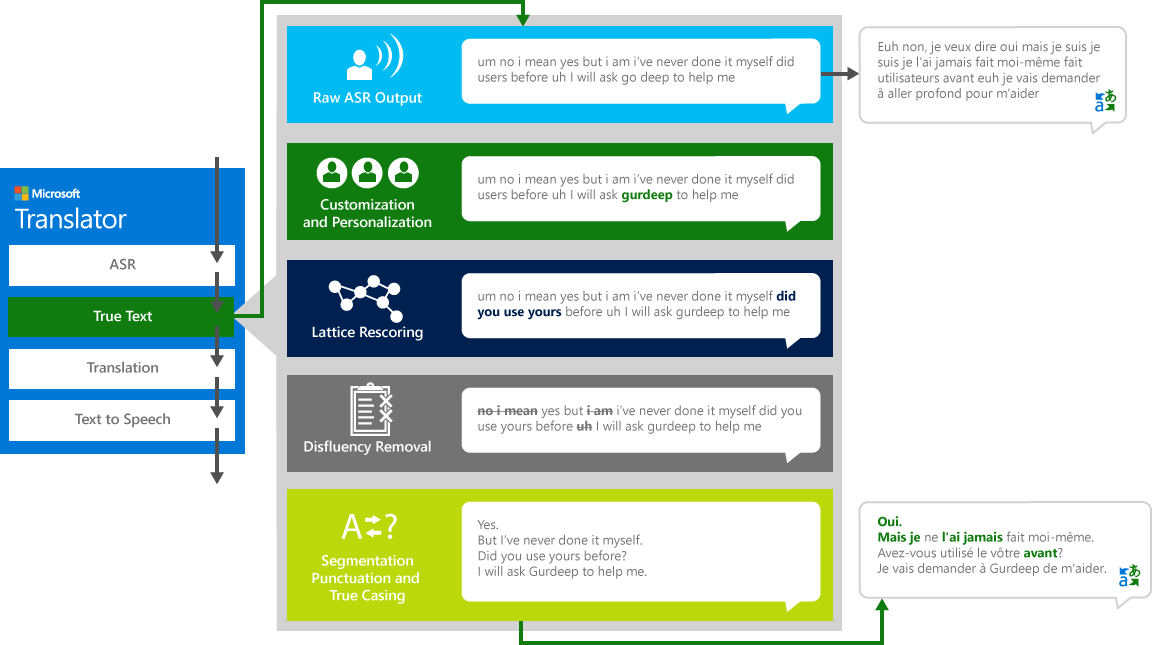
- Reconhecimento de fala, para converter áudio em texto
- TrueText: Uma tecnologia da Microsoft que normaliza o texto para torná-lo mais apropriado para a tradução
- Tradução por meio do mecanismo de tradução de texto descrito acima, mas com modelos de tradução especialmente desenvolvidos para conversas faladas na vida real
- Text-to-speech, quando necessário, para produzir o áudio traduzido.

Reconhecimento automático de fala (ASR)
O reconhecimento automático de fala (ASR) é realizado por meio de um sistema de rede neural (NN) treinado na análise de milhares de horas de áudio de fala recebida. Esse modelo é treinado em interações entre humanos, e não em comandos entre humanos e máquinas, produzindo um reconhecimento de fala otimizado para conversas normais. Para conseguir isso, são necessários muito mais dados e uma DNN maior do que os ASRs tradicionais entre humanos e máquinas.
Saiba mais sobre Serviços de fala para texto da Microsoft.
TrueText
Como seres humanos conversando com outros seres humanos, não falamos de forma tão perfeita, clara ou organizada quanto pensamos. Com a tecnologia TrueText, o texto literal é transformado para refletir melhor a intenção do usuário, removendo disfluências de fala (palavras de preenchimento), como "um "s, "ah "s, "e "s, "como "s, gaguejos e repetições. O texto também se torna mais legível e traduzível com a adição de quebras de frases, pontuação adequada e letras maiúsculas. Para alcançar esses resultados, usamos as décadas de trabalho em tecnologias de linguagem que desenvolvemos a partir do Translator para criar o TrueText. O diagrama a seguir mostra, por meio de um exemplo real, as várias transformações que o TrueText opera para normalizar esse texto literal.
Tradução
O texto é então traduzido para qualquer um dos idiomas e dialetos apoiado pelo Tradutor.
As traduções que usam a API de tradução de fala (como desenvolvedor) ou em um aplicativo ou serviço de tradução de fala são alimentadas com as mais novas traduções baseadas em rede neural para todos os idiomas suportados por entrada de fala (consulte aqui para obter a lista completa). Esses modelos também foram criados expandindo os modelos atuais de tradução treinados principalmente em texto escrito, com mais corpora de texto falado para criar um modelo melhor para tipos de traduções de conversas faladas. Esses modelos também estão disponíveis no site Categoria padrão "fala" da API de tradução de texto tradicional.
Para todos os idiomas não compatíveis com a tradução neural, é realizada a tradução SMT tradicional.
Texto para fala
Se o idioma de destino for um dos 18 idiomas compatíveis com conversão de texto em fala idiomase o caso de uso requer uma saída de áudio, o texto é então convertido em saída de fala usando a síntese de fala. Esse estágio é omitido em cenários de tradução de fala para texto.
Saiba mais sobre Serviços de texto para fala da Microsoft.
Pesquisa
Veja os trabalhos de pesquisa mais recentes da equipe do Microsoft Translator.
- Tradução automática neural universal para idiomas com recursos extremamente baixos
- Alcançando a paridade humana na tradução automática de notícias do chinês para o inglês
- Tradução de linguagem falada com reconhecimento de gênero aplicada ao inglês-árabe
- Dados sintéticos para tradução automática neural de dialetos falados



