
Tłumaczenie maszynowe
Co to jest tłumaczenie maszynowe?
Systemy tłumaczenia maszynowego to aplikacje lub usługi online korzystające z technologii uczenia maszynowego w celu translacji dużych ilości tekstu z i do któregokolwiek z obsługiwanych języków. Usługa tłumaczy tekst "źródłowy" z jednego języka na inny język "docelowy".
Chociaż koncepcje związane z technologią tłumaczenia maszynowego i interfejsami, które mają być używane, są stosunkowo proste, to nauka i technologie są bardzo skomplikowane i łączą w sobie kilka wiodących technologii, w szczególności głębokiego uczenia się ( Sztuczna inteligencja), Big Data, językoznawstwo, Cloud Computing, i Web API.
Od początku 2010, Nowa technologia sztucznej inteligencji, głębokie sieci neuronowe (aka Deep Learning), pozwoliła technologii rozpoznawania mowy, aby osiągnąć poziom jakości, które pozwoliły zespół Microsoft Translator połączyć rozpoznawanie mowy z jego technologii tłumaczenia tekstu, aby uruchomić nową technologię tłumaczenia mowy.
Historycznie podstawowa technika uczenia maszynowego wykorzystywana w przemyśle była statystycznym przekładem maszynowym (SMT). Firma SMT wykorzystuje zaawansowaną analizę statystyczną, aby oszacować najlepsze możliwe tłumaczenia dla danego słowa w kontekście kilku słów. Firma SMT została użyta od połowy 2000 roku przez wszystkich głównych dostawców usług tłumaczeniowych, w tym Microsoft.
Pojawienie się neuronowe tłumaczenie maszynowe (NMT) spowodował radykalne zmiany w technologii tłumaczeniowych, w wyniku znacznie wyższej jakości tłumaczenia. Ta technologia tłumaczenia rozpoczęła wdrażanie dla użytkowników i deweloperów w Ostatnia część 2016.
Technologie tłumaczeniowe SMT i NMT mają dwa elementy wspólne:
- Oba wymagają dużej ilości pre-ludzkie przetłumaczone treści (do milionów przetłumaczonych zdań) do szkolenia systemów.
- Nie działają jako słowniki dwujęzyczne, tłumaczenie słów na podstawie listy potencjalnych tłumaczeń, ale Tłumacz na podstawie kontekstu słowa, które jest używane w zdaniu.
Co to jest Tłumacz?
Usługi tłumacza i mowy, część Usługi poznawcze Kolekcja interfejsów API, to usługi tłumaczenia maszynowego firmy Microsoft.
Tłumaczenie tekstu
Translator jest używany przez grupy Microsoft od 2007 roku i jest dostępny jako API dla klientów od 2011 roku. Translator jest szeroko stosowany w firmie Microsoft. Jest on włączony do zespołów ds. lokalizacji produktów, wsparcia i komunikacji online. Ta sama usługa jest również dostępna, bez dodatkowych kosztów, ze znanych produktów firmy Microsoft, takich jak Bing, Cortana, Microsoft Edge, Office, Programu sharepoint, Skypei Yammer.
Translator może być używany w aplikacjach internetowych lub klienckich na dowolnej platformie sprzętowej i z dowolnym systemem operacyjnym do wykonywania tłumaczeń językowych i innych operacji związanych z językiem, takich jak wykrywanie języka, zamiana tekstu na mowę lub słownik.
Wykorzystując standard branżowy technologii REST, programista wysyła tekst źródłowy (lub audio do tłumaczenia mowy) do usługi z parametrem wskazującym język docelowy, a usługa odsyła przetłumaczony tekst dla klienta lub aplikacji internetowej do użycia.
Usługa Translator to usługa platformy Azure hostowana w centrach danych firmy Microsoft i korzysta z zabezpieczeń, skalowalności, niezawodności i nieprzerwanej dostępności, które również otrzymują inne usługi w chmurze firmy Microsoft.
Tłumaczenie mowy
Technologia tłumaczenia mowy została uruchomiona pod koniec 2014 r., począwszy od Skype Translator, i jest dostępna jako otwarty interfejs API dla klientów od początku 2016 r. Jest zintegrowany z funkcją microsoft translator na żywo, Skype, transmisja spotkania Skype i aplikacje Microsoft Translator dla systemów Android i iOS.
Tłumaczenie mowy jest teraz dostępne za pośrednictwem programu Microsoft Speech — kompleksowego zestawu w pełni konfigurowalnych usług do rozpoznawania mowy, tłumaczenia mowy i syntezy mowy (Text-to-Speech).
Jak działa tłumaczenie tekstu?
Istnieją dwie główne technologie używane do tłumaczenia tekstów: dziedzictwo, statystyczne tłumaczenie maszynowe (SMT) i nowsza generacja, tłumaczenie maszynowe neuronowe (NMT).
Statystyczne tłumaczenie maszynowe
Implementacja statystycznego tłumaczenia maszynowego (SMT) firmy Translator opiera się na ponad dekadzie badań nad językiem naturalnym w firmie Microsoft. Zamiast pisać ręcznie robione reguły do tłumaczenia między językami, nowoczesne systemy tłumaczeniowe podchodzą do tłumaczenia jako problemu uczenia się transformacji tekstu między językami z istniejących tłumaczeń ludzkich i wykorzystania najnowszych osiągnięć w stosowanych statystykach i uczeniu maszynowym.
Tak zwana "równoległa corpora" działa jako nowoczesny kamień Rosetta w ogromnych proporcjach, zapewniając tłumaczenia słowne, frazowe i idiomatyczne w kontekście wielu par językowych i domen. Statystyczne techniki modelowania i wydajne algorytmy pomagają komputerowi rozwiązać problem rozszyfrowania (wykrywania korespondencji między językiem źródłowym a docelowym w danych szkoleniowych) i dekodowania (znalezienie najlepszego tłumaczenia nowego zdania wejściowego). Tłumacz łączy moc metod statystycznych z informacjami językowymi, aby tworzyć modele, które lepiej uogólniają i prowadzą do bardziej zrozumiałych tłumaczeń.
Ze względu na takie podejście, które nie polega na słownikach lub regułach gramatycznych, zapewnia najlepsze tłumaczenia fraz, gdzie może korzystać z kontekstu wokół danego słowa w porównaniu do wykonywania pojedynczych tłumaczeń słów. W przypadku tłumaczeń pojedynczych słów słownik dwujęzyczny został opracowany i dostępny www.Bing.com/translator.
Translacja maszyn neuronowych
Ciągłe ulepszenia tłumaczenia są ważne. Jednak od połowy 2010 roku nastąpiła poprawa wydajności technologii SMT. Wykorzystując skalę i moc superkomputera AI firmy Microsoft, a konkretnie microsoft cognitive toolkit, Translator oferuje teraz sieć neuronową (LSTM) oparte na tłumaczeniu, które umożliwia nową dekadę poprawy jakości tłumaczenia.
Te modele sieci neuronowych są dostępne dla wszystkich języków mowy za pośrednictwem usługi mowy na platformie Azure i za pośrednictwem tekstowego interfejsu API przy użyciu identyfikatora kategorii "generalnn".
Translacje sieci neuronowych zasadniczo różnią się w zależności od sposobu ich wykonania w porównaniu z tradycyjnymi SMT.
Następująca animacja przedstawia różne kroki tłumaczenia sieci neuronowe przejść do tłumaczenia zdanie. Z powodu tego podejścia, tłumaczenie zajmie w kontekście pełne zdanie, w porównaniu tylko kilka słów przesuwnych okna, że technologia SMT wykorzystuje i będzie produkować więcej płynnych i ludzkich tłumaczeń szuka.
Na podstawie szkolenia sieci neuronowe, każde słowo jest kodowane wzdłuż 500-wymiary wektor (a) reprezentujących jego unikalne cechy w danej pary językowej (np. angielski i chiński). Na podstawie par język używany do szkolenia, Sieć neuronowa będzie samodzielnie zdefiniować, jakie powinny być te wymiary. Mogą kodować proste koncepcje, takie jak płeć (kobiecy, męski, neutralny), poziom uprzejmości (slang, casual, pisemne, formalne, itp.), rodzaj słowa (czasownik, rzeczownik, itp.), ale także wszelkie inne nieoczywiste cechy wynikające z danych szkoleniowych.
Kroki translacji sieci neuronowe przejść są następujące:
- Każde słowo, lub dokładniej 500-wektor wymiaru reprezentujących go, przechodzi przez pierwszą warstwę "neuronów", które będą kodować je w wektorze wymiarze 1000 (b) reprezentujących słowo w kontekście innych słów w zdaniu.
- Gdy wszystkie słowa zostały zakodowane jeden raz do tych wektorów wymiar 1000, proces jest powtarzany kilka razy, każda warstwa pozwala na lepsze dostrajanie tego 1000-wymiar reprezentacji słowa w kontekście pełnego zdania (w przeciwieństwie do SMT Technologia, która może brać pod uwagę tylko 3 do 5 słów okno)
- Ostateczna matryca wyjściowa jest następnie wykorzystywana przez warstwę uwagi (tj. algorytm oprogramowania), która będzie wykorzystywać zarówno tę ostateczną matrycę wyjściową, jak i dane wyjściowe wcześniej przetłumaczonych słów w celu określenia, które słowo, z zdania źródłowego, powinno zostać przetłumaczone dalej. Będzie również używać tych obliczeń potencjalnie usunąć niepotrzebne słowa w języku docelowym.
- Warstwa Decoder (translation), tłumaczy zaznaczony wyraz (lub dokładniej wektor wymiaru 1000 reprezentującego to słowo w kontekście pełnego zdania) w najbardziej odpowiednim dla niego języku docelowym. Dane wyjściowe tej ostatniej warstwy (c) są następnie ponownie wprowadzane do warstwy uwagi, aby obliczyć, które następne słowo z zdania źródłowego powinno być przetłumaczone.

W przykładzie przedstawionym w animacji kontekstowy 1000-model wymiaru "Tthe"będzie kodować, że rzeczownik (House) jest żeńskim słowem w języku francuskim (La Maison). Umożliwi to odpowiednie tłumaczenie dla "Tthe"być"La"i nie"Le"(pojedyncza, męska) lub"Les"(liczba mnoga), gdy osiągnie warstwę dekoder (tłumaczenie).
Algorytm uwagi będzie również obliczyć, w oparciu o słowo (s) wcześniej przetłumaczone (w tym przypadku "Tthe"), że następne słowo, które ma zostać przetłumaczone, powinno być przedmiotem ("House"), a nie przymiotnik ("Niebieski"). W może to osiągnąć, ponieważ system dowiedział się, że angielski i francuski odwrócić kolejność tych słów w zdaniach. Oznaczałoby to również, że gdyby przymiotnik miał być "Duże"zamiast koloru, że nie powinien odwrócić je ("duży dom"= >"La Grande Maison").
Dzięki takiemu podejściu, ostateczne wyjście jest, w większości przypadków, bardziej płynne i bardziej zbliżone do ludzkiego tłumaczenia niż w przypadku tłumaczenia na bazie SMT.
Jak działa Tłumaczenie mowy?
Tłumacz jest również zdolny do tłumaczenia mowy. Technologia ta jest widoczna w funkcji translatora na żywo (http://translate.it), Tłumacz aplikacje, Skype Tłumacz i jest początkowo udostępniane tylko za pośrednictwem funkcji Tłumacz Skype i w aplikacji Microsoft Translator na iOS i Android, ta funkcja jest teraz dostępna dla deweloperów z najnowszą wersją Open Interfejs API oparty na REST dostępny w portalu Azure.
Chociaż może się wydawać, że proces prosto do przodu na pierwszy rzut oka zbudować technologię tłumaczenia mowy z istniejących klocków technologii, to wymagało dużo więcej pracy niż zwykłe podłączenie istniejącego "tradycyjnego" człowieka do maszyny rozpoznawanie mowy do istniejącego tłumaczenia tekstowego.
Aby prawidłowo przetłumaczyć mowę "source" z jednego języka na inny język "docelowy", system przechodzi przez proces czterech etapów.
- Rozpoznawanie mowy, przekształcanie dźwięku w tekst
- TrueText: technologia firmy Microsoft, która normalizuje tekst, aby uczynić go bardziej odpowiednim do tłumaczenia
- Tłumaczenie przez silnik tłumaczeń tekstowych opisanych powyżej, ale na modelach tłumaczeniowych opracowanych specjalnie dla rozmów głosowych na prawdziwe życie
- Text-to-Speech, w razie potrzeby, do produkcji przetłumaczonych audio.

Automatyczne rozpoznawanie mowy (ASR)
Automatyczne rozpoznawanie mowy (ASR) jest wykonywane przy użyciu systemu neuronowe sieci (nn) przeszkolonych na analizowanie tysięcy godzin przychodzących mowy audio. Ten model jest przeszkolony w zakresie interakcji człowieka z ludźmi, a nie poleceniami od człowieka do komputera, produkując rozpoznawanie mowy zoptymalizowane pod kątem normalnych konwersacji. Aby to osiągnąć, potrzebne są znacznie więcej danych, jak również większe DNN niż tradycyjne ASRs człowieka do maszyny.
Dowiedz się więcej o Przemówienie do usług tekstowych firmy Microsoft.
TrueText
Jako ludzie rozmawiając z innymi ludźmi, nie mówimy tak doskonale, jasno lub starannie, jak często myślimy, że robimy. Dzięki technologii TrueText, tekst dosłowny jest przekształcany w celu dokładniejszego odzwierciedlenia intencji użytkownika poprzez usunięcie disfluencies mowy (słów wypełniacza), takich jak "UM", "Ah", "i" s ", takich jak" s, zacina się i powtórzenia. Tekst jest również bardziej czytelny i przetłumaczyć, dodając podziały zdań, właściwą interpunkcję i wielkość liter. Aby osiągnąć te wyniki, wykorzystano kilkadziesiąt lat pracy nad technologiami językowymi, opracowaliśmy od tłumacza do tworzenia TrueText. Poniższy diagram przedstawia, poprzez rzeczywisty przykład, różne TrueText transformacji działa w celu normalizacji tego literału tekstu.
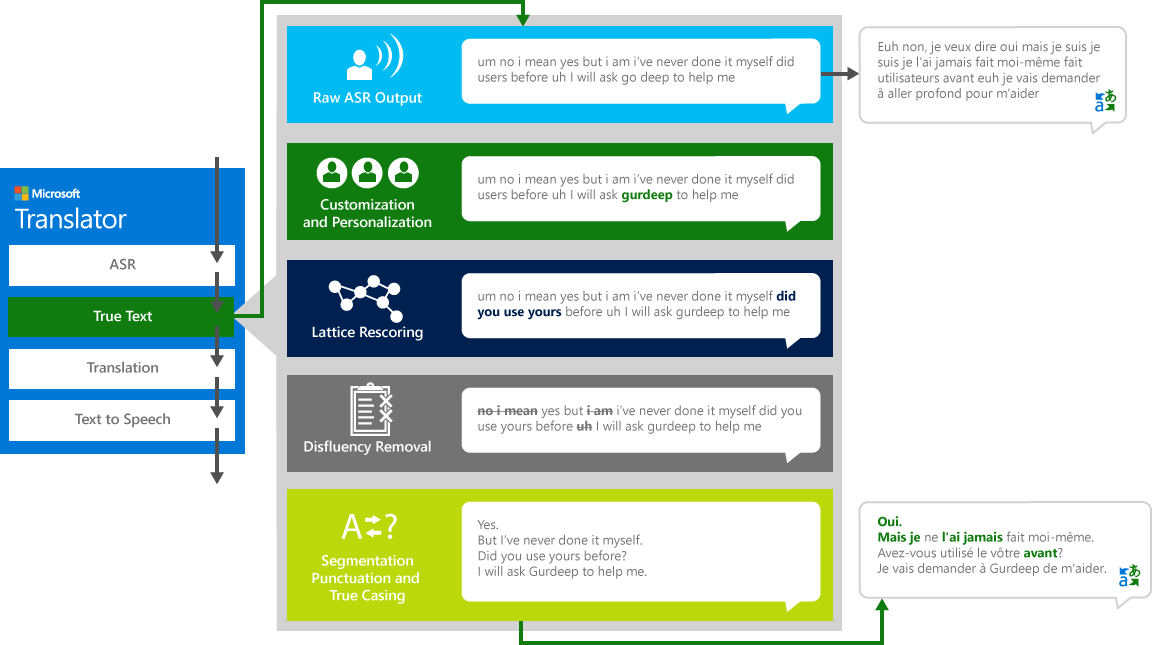
Tłumacz
Tekst jest następnie tłumaczony na języków i dialektów obsługiwane przez tłumacza.
Tłumaczenia za pomocą interfejsu API translacji mowy (jako deweloper) lub w aplikacji lub usłudze tłumaczenia mowy są zasilane z najnowszych tłumaczeń opartych na sieci neuronowych dla wszystkich języków obsługiwanych przez mowę (patrz tutaj pełną listę). Modele te zostały również zbudowane poprzez poszerzenie obecnego, przeważnie przeszkolonych tekstów napisanych w formie pisemnej, z bardziej mówionymi korpusami, aby zbudować lepszy model dla mówionej konwersacji typów tłumaczeń. Modele te są również dostępne Kategoria standardowa "mowa" interfejsu API translacji tekstu tradycyjnego.
W przypadku języków, które nie są obsługiwane przez translację neuronalną, wykonywane jest tradycyjne tłumaczenie SMT.
Tekst na mowę
Jeśli język docelowy jest jednym z 18 obsługiwanych text-to-Speech Języki, a przypadek użycia wymaga wyjścia audio, tekst jest następnie konwertowany na dane wyjściowe mowy za pomocą syntezy mowy. Ten etap jest pominięty w scenariuszach translacji mowy na tekst.
Dowiedz się więcej o Usługi syntezatora mowy firmy Microsoft.
Badania
Zobacz najnowsze prace badawcze z zespołu Microsoft Translator.
- Uniwersalna maszyna neuronowa tłumaczenie dla bardzo niskich językach zasobów
- Osiągnięcie parytetu człowieka na automatyczne tłumaczenie wiadomości chińskich na angielski
- Świadomość płci w języku mówionym stosowane w języku angielskim-arabski
- Syntetyczne dane dla maszyny neuronowe tłumaczenie mówi-dialektów



